上一篇文章用官方的kubeadm 1.16.1 工具部署一个单节点master node的kubernetes cluster的方法。这篇文章按官方文档部署一个高可用的kubernetes.
Server Lists
Server77 Ubuntu 18.04LTS (Master1) 172.18.194.77 Server78 Ubuntu 18.04LTS (Master2) 172.18.194.78 Server79 Ubuntu 18.04LTS (Master3) 172.18.194.79
HA kubernetes cluster diagram structure
下面是官网建议的,三台master node叠加etcd的架构图: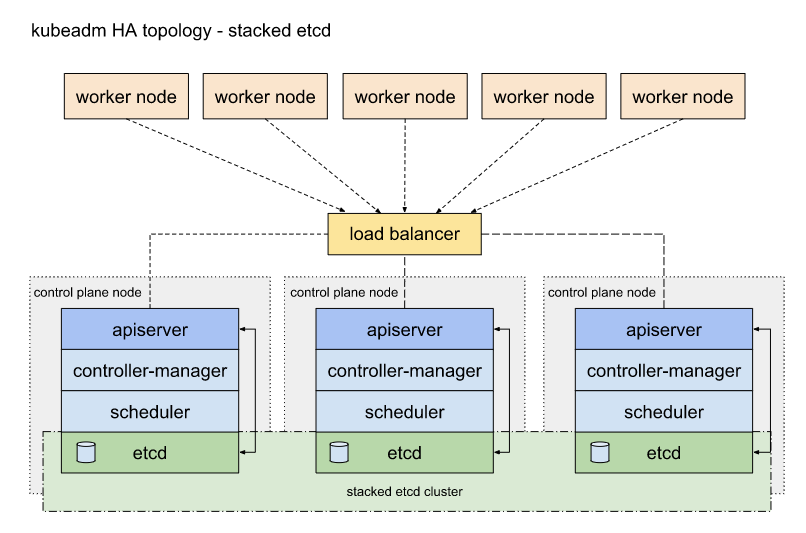
下面是我按上面架构,用kubeadm安装的有三个master node叠加etcd的高可用kubernetes cluster 架构图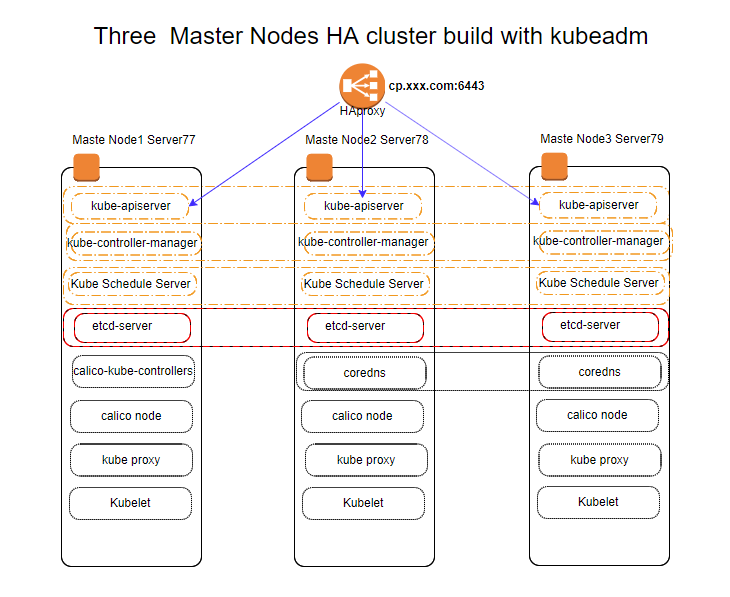
在上面的架构图看到去有点复杂,做一下说明吧:
- HAproxy 用来把访问cp.xxx.com:6443的kube-apiserver的请求分发到三台Master Node的kube-apiserver的6443端口上,用作负载均衡。这个HAproxy也可以不用,直接用DNS把cp.xxx.com这个域名分别解到三台Master Node的IP上,也可以实现round-robin DNS负载均衡。
- kube-apiserver 是master node上的组件,分布在每一个master node上,提供API接口服务。任何一个master node 服务器挂掉,都不会影响整个kubernetes cluster的正常运行。
- kube-controller-manager/kube-schedule 是master node上的组件,一样分别运行在三台master node上,提供Pod的控制和调度服务。
- etcd 组件是一个高可用的一致性 key value 存储,同样会分别运行在三个master node上(etcd 可以是放在master node上,也可以在其它服务器上独立部署,一个高可用的etcd 至少要3台独立的服务器)。
- kubelet 是node 组件,分布在各个node上,用来保证node上的containers与PodSpecs中的描述相符合,并正常运行。我这边的master node也用做node来跑app pod。
- kube-proxy 是一个网络代理,跑在每一个node上,用来做ServiceIP和Node内部同一个Service上的多个pod之间代理。
- calico-node 是一个add-on CNI,用来实现pod之间的沟通,在每个node上运行。
- calico-kube-controllers 是calico控制pod,可以运行在任何node上。
下图是整个kubernetes cluster 结构图,方便大家理解kubernetes 内部各组件之间的关系:
Create load balancer for kube-apiserver
在我的架构中,前端Loadbalance 我用了HAproxy,下面是我的haproxy.conf的配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29global
log /dev/log local0
log /dev/log local1
maxconn 32768
user haproxy
group haproxy
stats socket /var/run/haproxy.sock
defaults
log global
mode http
retries 3
timeout client 50s
timeout connect 5s
timeout server 50s
option dontlognull
option http-server-close
option redispatch
balance roundrobin
option forwardfor
frontend kube-apiserver-6443
bind *:6443
mode tcp
log global
use_backend kube-apiserver
backend kube-apiserver
mode tcp
server ip_172.18.194.77_6443 172.18.194.77:6443 weight 1 maxconn 3000 check
server ip_172.18.194.78_6443 172.18.194.78:6443 weight 1 maxconn 3000 check
server ip_172.18.194.79_6443 172.18.194.79:6443 weight 1 maxconn 3000 check
当然,最方便的方法是使用DNS round-robin 来实现负载均衡,把三个master node的IP解到cp.xxx.com这个域名上。
Steps for the first control plane node (master node1)
下面,我先在Server77上来用kubeadm init 初始化第一个master node.1
root@server77:~# kubeadm init --image-repository registry.aliyuncs.com/google_containers --control-plane-endpoint "cp.xxx.com:6443" --pod-network-cidr=192.168.0.0/16 --upload-certs
说明:
–image-repository registry.aliyuncs.com/ 这个设置阿里云做镜像下载站点,可以加速下载速度,减少部署时间
–control-plane-endpoint 是我的HAproxy的域名及端口。
–pload-certs 这个设置会把证书加密后放到kubeadm-certs Secret中,这样,在加其它master node时,就不用手动去CP这个master node证书了,方便很多。
–pod-network-cidr=192.168.0.0/16 这个是calico CNI要用的。
最后,记得把命令输出的最后几行记录下来,特别是有 kubeadm join 的那两个命令,这两个命令,一个是用来加入control-plane node(master node)的,另一个是用来加来worker nodes的,如下:
1 | You can now join any number of the control-plane node running the following command on each as root: |
然后,是安装CNI,我这里选择使用Calico,部署命令如下:1
2
3# 我这里选择了最新的3.9版本,在kubernetes1.16.1上运行没有问题
#kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
kubectl apply -f https://docs.projectcalico.org/v3.9/manifests/calico.yaml
安装完成Calico CNI后,查看master node 的状态1
2
3root@server77:~# kubectl get node
NAME STATUS ROLES AGE VERSION
server77 Ready master 42h v1.16.1
最后,使用下面的命令,让master node 上也可以分配pod1
kubectl taint nodes --all node-role.kubernetes.io/master-
Steps for the rest of the control plane nodes (other master nodes)
在第一个master node 在server77上安装完成后,我们继续在server78/server79上部署control plane,就用上面记录的 kubeadm join命令:1
2
3
4
5kubeadm join cp.xxx.com:6443 --token ap9hs3.rvq3cjxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:c3362088e1c997102750d395d9c775b84d5eae578f87b198527383xxxxxxxxxx \
--control-plane --certificate-key 4d73d09a2916ce68beaaa5b77636365970d00b50bf8ca965f2c030xxxxxxxxxx
# The --control-plane flag tells kubeadm join to create a new control plane. 这个参数用来加入control plane node(master node),而不是用来加入worker node.
# The --certificate-key ... will cause the control plane certificates to be downloaded from the kubeadm-certs Secret in the cluster and be decrypted using the given key. 这个参数是用来解密kubeadm-certs 用的,里面记录了kubeadm init时,在第一个control plane生成的,其它后加入的control plane 要使用的所有相关证书
然后,还是安装CNI,我这里选择使用Calico,部署命令如下:1
2
3# 我这里选择了最新的3.9版本,在kubernetes1.16.1上运行没有问题
#kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
kubectl apply -f https://docs.projectcalico.org/v3.9/manifests/calico.yaml
最后,使用下面的命令,让这两个control plane 上也可以分配pod1
kubectl taint nodes --all node-role.kubernetes.io/master-
在完成上面部署后,就可以用下面的命令查看整个kubernetes的状态了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# 查看三个加好的control plane node
root@server77:~/kubeadmin# kubectl get node
NAME STATUS ROLES AGE VERSION
server77 Ready master 3d8h v1.16.1
server78 Ready master 3d7h v1.16.1
server79 Ready master 3d7h v1.16.1
# 查看这三个control plane node 上所有pod
root@server77:~/kubeadmin# kubectl get pod --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-b7fb7899c-z5kjj 1/1 Running 0 2d14h 192.168.82.65 server79 <none> <none>
kube-system calico-node-jmn7n 1/1 Running 0 3d7h 172.18.194.78 server78 <none> <none>
kube-system calico-node-p9stg 1/1 Running 0 3d7h 172.18.194.77 server77 <none> <none>
kube-system calico-node-vr9gw 1/1 Running 0 3d7h 172.18.194.79 server79 <none> <none>
kube-system coredns-58cc8c89f4-2mwn7 1/1 Running 0 2d14h 192.168.82.66 server79 <none> <none>
kube-system coredns-58cc8c89f4-zzmnb 1/1 Running 0 2d14h 192.168.215.65 server77 <none> <none>
kube-system etcd-server77 1/1 Running 2 3d8h 172.18.194.77 server77 <none> <none>
kube-system etcd-server78 1/1 Running 10 3d7h 172.18.194.78 server78 <none> <none>
kube-system etcd-server79 1/1 Running 5 3d7h 172.18.194.79 server79 <none> <none>
kube-system kube-apiserver-server77 1/1 Running 4 3d8h 172.18.194.77 server77 <none> <none>
kube-system kube-apiserver-server78 1/1 Running 11 3d7h 172.18.194.78 server78 <none> <none>
kube-system kube-apiserver-server79 1/1 Running 5 3d7h 172.18.194.79 server79 <none> <none>
kube-system kube-controller-manager-server77 1/1 Running 2 3d8h 172.18.194.77 server77 <none> <none>
kube-system kube-controller-manager-server78 1/1 Running 0 3d7h 172.18.194.78 server78 <none> <none>
kube-system kube-controller-manager-server79 1/1 Running 0 3d7h 172.18.194.79 server79 <none> <none>
kube-system kube-proxy-4rwr5 1/1 Running 0 3d7h 172.18.194.79 server79 <none> <none>
kube-system kube-proxy-bfwc7 1/1 Running 0 3d7h 172.18.194.78 server78 <none> <none>
kube-system kube-proxy-hqm2j 1/1 Running 0 3d8h 172.18.194.77 server77 <none> <none>
kube-system kube-scheduler-server77 1/1 Running 2 3d8h 172.18.194.77 server77 <none> <none>
kube-system kube-scheduler-server78 1/1 Running 1 3d7h 172.18.194.78 server78 <none> <none>
kube-system kube-scheduler-server79 1/1 Running 0 3d7h 172.18.194.79 server79 <none> <none>
这样,一个有三个control plane nodes的高可用的,并且可以在上面部署pod的kubernetes cluster就建好了。
Kubernetes HA cluster control plane fail test
下面,我们试一下,这个叠加etcd(etcd 可独立部署)的三台control plane node,是否是真的高可用:
1.在没有出现问题的情况下,整个cluster信息如下图,coredns pod 分别在server77 和 server79上,calico-kube-controllers也在server79上:
2.现在我们把server79的网络拔掉,看看整个cluster是否还可用?再看看server79上的coredns pod会怎么样?如下图:
从上图可以看出:
1.server79已经处在NotReady状态。
2.本来在Server79上的 coredns和calico-kube-controllers两个pod处在了Terminating状态,并分别在server78上生成了两个新的pod,用来替代在server79上Terminating的两个pod.
可以用下面的etcdctl命令可以查看在挂掉一台master node的情况下,etcd集群是可用的。
下面,我们关掉这个叠加etcd(etcd 可独立部署)的三台control plane node中的两台,试试看这个kubernetes cluster是否还可以用。
在断掉两台control plane node网络连接的情况下,如下图:
从上图可以看出,在关掉三台中的两台control plane node的情况下,整个cluster已经不可用,etcd 已经无法选出LEADER,etcd 已经不可用。在etcd不可用的情况下,kube-apiserver无法从etcd获取数据,整个kubernetes cluster也无法获取任何数据,也无法进行任何操作了。
下面,恢复上面二台机器的网络连接,看cluster是否会恢复:
从上图看,在cluster在两台control plane 网连接恢复的情况下,整个kubernetes cluster 自动恢复了(注:恢复的过程会要一点时间,起先恢复的node的kube-apiserver会处在CrashLoopBackOff状态,过会就会恢复。
结论:1.在关掉三台kubernetes cluster control plane node中的任意一台的网络连接,整个cluster是可以正常工作的。被关掉了那台control plane node上的pod会迁移到其它 control plane node上(设置三台control plane node上都可以部署pod)。2.在关掉三台中的两台control plane node的网络连接的情况下,整个cluster不可用。3.把两台关掉是网络连接的机器恢复后,整个cluster会自动恢复正常。
最后,加个图,是一个pod在kubernetes cluster中的创建过过程。用来大概的说明kubernetes各服务如何顺序工作,生成一个pod的:

