这两天在配合测评中心做我们的一个老项目的终审评测,其中有一些网站的技术指标要达到测评中心的要求。其中,有个登录接口,要求可以在500用户并发的情况下,TPS达到860以上,而且成功率要在99.5%以上。刚开始以为使用高配的云主机,应该可以轻松达到性能要求。没想到,测评中心用loadrunner一压,500用户并发下,TPS只有100多,而且成功率只有85%, 服务器CPU load5到了500多,我去。
服务器端优化
这个是老本行,先分析自己的原因。服务器端是ubuntu16.04_LTS nginx+php7.0-fpm+mysql5.7,程序是php写的。
1、刚开始以为云主机配置低,把云主机的配置升成 16core/32G (问题没有解决)
2、在压测时,用netstat -an | grep TIME_WAIT | wc -l 命令查看,发现TCP的TIME_WAIT达到了5W多个,做内核参数优化(自从用了云主机,就很久没有去优化内核参数了,一直以为云主机已经优化的很好了,其实不是,在大压力下要改些参数)。1
2
3
4
5
6
7
8
9#在/etc/sysctl.conf中增加下面的参数,然后sysctl -p
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_max_tw_buckets = 5000
更改内核参数后,TCP TIME_WAIT 被控制在了5000左右。但不是不行,CPUload依然很高。
3、发现程序日志中报错,显示连接mysql 数据库被拒绝。查看mysql的配置,发现最大连接数为200,连接mysql ,设置最大连接为1024.1
set GLOBAL max_connections=1024
更改完成后,发现还是达不到要求 。
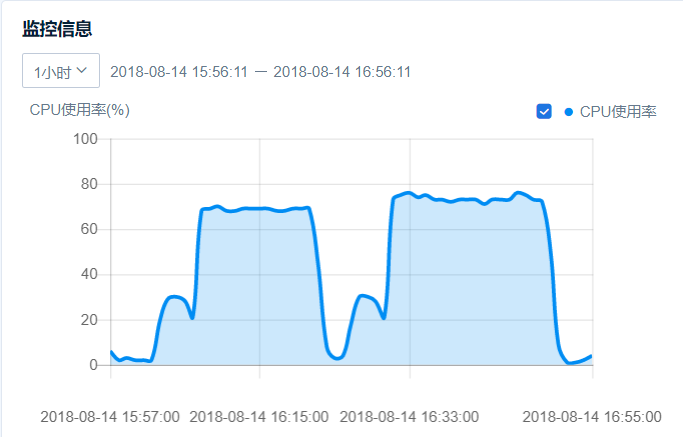
4、联系开发,更新程序 ,把认证相关的数据第一次从DB中读出来后,直接放memcache中,再次访问,直接从memcache读取,这时性能已经可以达到1800TPS了,但是新问题又出现了,就是服务器CPULOAD 直接上500,请求成功率只有98.7%,达不到99.5%以上的成功率要求。
重点说说 loadrunner Client端优化
Client端环境:
Client端软件: LoadRunner11
测试用机器: 为了排除网络干扰,我们专门用了一台测试用的2core、4G的云主机和被测试服务器在同一内网进行测试。
问题分析:
上面的问题是因为loadrunner 在500Vuser并发的情况下: 当一个Vuser收到服务器完成的请求后,马上就会发送第二个,也就是说,Vuser会用最快的速度向服务器发请求,当服务器达到一个性能极限时,就会出现上面的情况,TPS很高,但抖动也很大,服务器CPU_LOAD5 急增到500左右,后台php-fpm程序应无法响应请求,前台nginx 直接返回502的情况发生。
说白了,就是loadrunner没有控制每个Vuser向服务器发启请求的频率。举个例子,你上报的测试指标是”这个人挑100斤担子,走路不摇晃”,而真实的测试方式的”这个人能挑多重就给你担多重(比如来个300斤),而且还要不摇晃”。这种压测方式 ,不管你多高性能的服务器,设计多合理的程序,都可以给你压出报错来,对吧?
有几种方式来减低Vuser的发包率:
1、降低Client端机器的配置,给个1core的机器,但不能精确发包率,从而控制TPS
2、降低Client端机器的带宽,和上面的缺点一样。
3、设置 Think Time,如果你是多个事务的请,可以在java Vuser脚本的Action和Action之间加入 Lr_think_time(0.1),0.1表示在两个事务之间加入0.1秒的间隔时间,来模拟用户在做完一个操作后,停一下,再做另一个操作。这个可以比较精准的进行客户端TPS控制,但如果只有一个事务,也是不行的。
4、设置Pacing,这个是Vuser在完成一个迭代后的间歇时间,可以控制到ms,因为我这边是单个事务,用下面的参数来控制.下图设置是在完成一次迭代后等待0.46秒。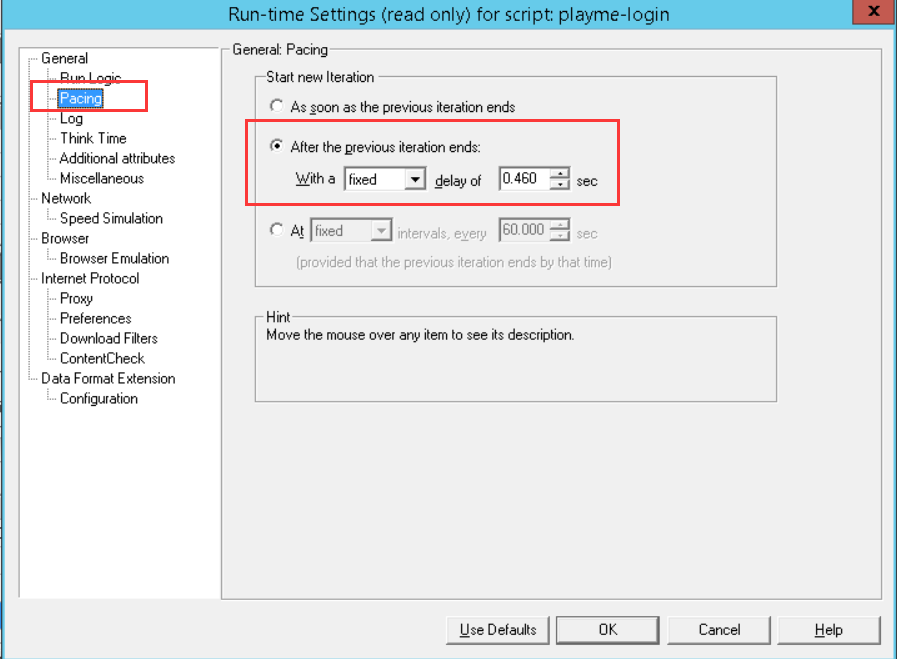
上面几个方法中,我使用了第4钟方法,把TPS成功的控制成了1000左右,而且服务器端CPU占用非常稳定的控制在了80%以下,完全达到了测试指标要求。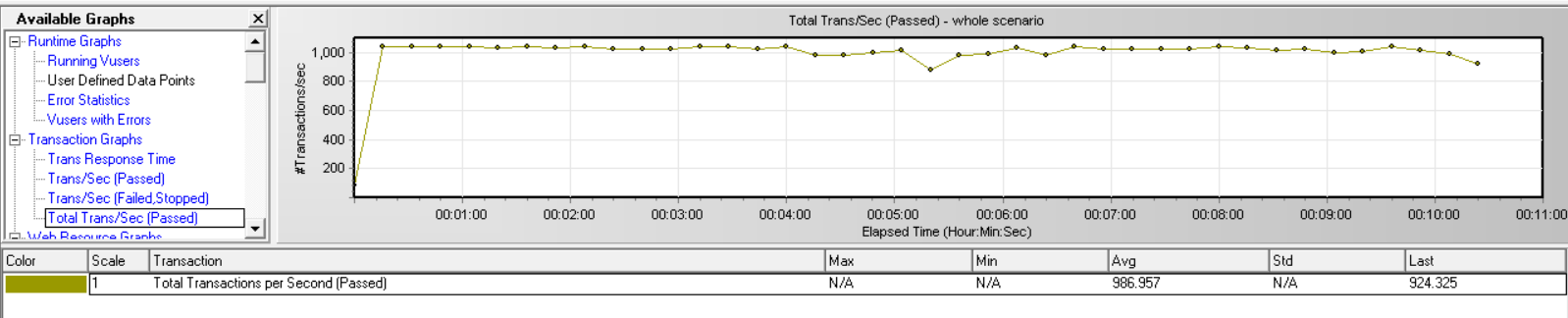
最后
发个关于Pacing设置的老贴子,让大家一起回味一下。

