这周碰到了一个很妖的问题,线上的一台服务器跑得好好的,公司访问过去80,就是时通时不通。不通的时候,所有的TCP端口都无法正常访问。但从公司外访问,又都是正常的。这个问题困扰了我们一周时间,原因是找问题找错了方向,去找了网络服务商
刚开始以为是我们公司的出口问题,让网络部门去联系数讯去查,联系电信去查,但怎么也查不出什么结果。后来,索性让数讯派人过来查,在公司的Firewall外单独配置了一个IP,但怎么访问都正常。切回到防火墙内,问题又重现了。查了防火墙日志,显示连接超时(AGE OUT)。这样一搞,一周时间过去了,还好应用还在测试阶段。
后来,发现线上两台服务器,一台是好的,一台有问题。互换IP后,有问题的还是原来的那台。所以,把问题指向了服务器端。在问题服务器上,进行tcpdump ,发现只能收到公司IP过来的SYN包,但服务器就是无ACK包的返回(公司外IP访问都正常)。对比两台机器上 netstat -s的结果,发现 passive connections rejected because of time stamp 的统计在好的机器上是没有的。哈,在google中搜索 “passive connections rejected because of time stamp”,问题马上找到了。
接下来我们来谈谈问题的原因:
先讲一下PAWS
PAWS全名Protect Againest Wrapped Sequence numbers,目的是解决在高带宽下,TCP序列号在一次会话中可能被重复使用而带来的问题。如图:
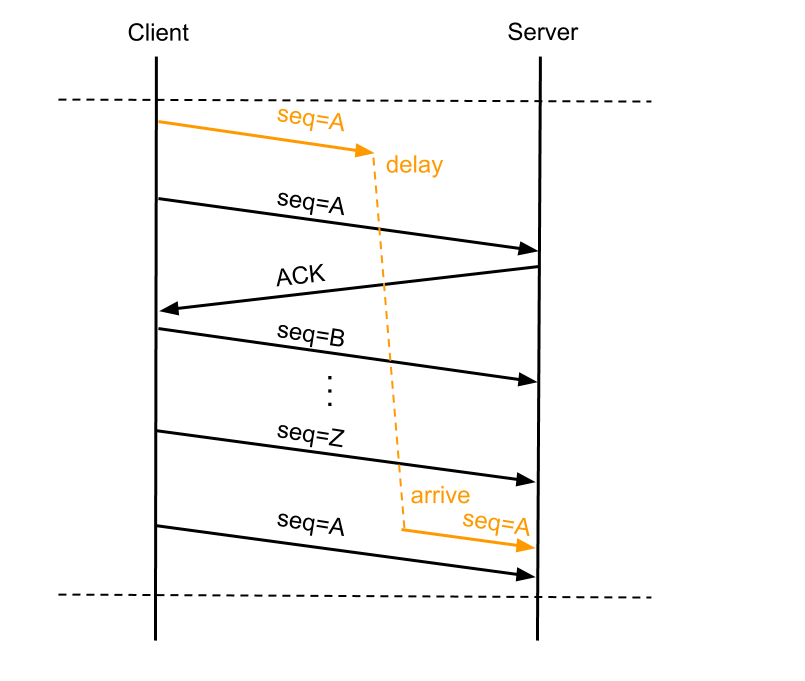
如上图所示,客户端发送的序列号为A的数据包A1因某些原因在网络中“迷路”,在一定时间没有到达服务端,客户端超时重传序列号为A的数据包A2,接下来假设带宽足够,传输用尽序列号空间,重新使用A,此时服务端等待的是序列号为A的数据包A3,而恰巧此时前面“迷路”的A1到达服务端,如果服务端仅靠序列号A就判断数据包合法,就会将错误的数据传递到用户态程序,造成程序异常。
PAWS要解决的就是上述问题,它依赖于timestamp机制,理论依据是:在一条正常的TCP流中,按序接收到的所有TCP数据包中的timestamp都应该是单调非递减的,这样就能判断那些timestamp小于当前TCP流已处理的最大timestamp值的报文是延迟到达的重复报文,可以予以丢弃。在上文的例子中,服务器已经处理数据包Z,而后到来的A1包的timestamp必然小于Z包的timestamp,因此服务端会丢弃迟到的A1包,等待正确的报文到来。
PAWS机制的实现关键是内核保存了Per-Connection的最近接收时间戳,如果加以改进,就可以用来优化服务器TIME_WAIT状态的快速回收。
TIME_WAIT状态是TCP四次挥手中主动关闭连接的一方需要进入的最后一个状态,并且通常需要在该状态保持2*MSL(报文最大生存时间),它存在的意义有两个:
1.可靠地实现TCP全双工连接的关闭:关闭连接的四次挥手过程中,最终的ACK由主动关闭连接的一方(称为A)发出,如果这个ACK丢失,对端(称为B)将重发FIN,如果A不维持连接的TIME_WAIT状态,而是直接进入CLOSED,则无法重传ACK,B端的连接因此不能及时可靠释放。
2.等待“迷路”的重复数据包在网络中因生存时间到期消失:通信双方A与B,A的数据包因“迷路”没有及时到达B,A会重发数据包,当A与B完成传输并断开连接后,如果A不维持TIME_WAIT状态2MSL时间,便有可能与B再次建立相同源端口和目的端口的“新连接”,而前一次连接中“迷路”的报文有可能在这时到达,并被B接收处理,造成异常,维持2MSL的目的就是等待前一次连接的数据包在网络中消失。
下面来说说,net.ipv4.tcp_tw_recycle这个内核参数的作用是通过PAWS实现TIME_WAIT快速回收:
在PAWS的理论基础上,如果内核保存Per-Host的最近接收时间戳,接收数据包时进行时间戳比对,就能避免TIME_WAIT意图解决的第二个问题:前一个连接的数据包在新连接中被当做有效数据包处理的情况。这样就没有必要维持TIME_WAIT状态2*MSL的时间来等待数据包消失,仅需要等待足够的RTO(超时重传),解决ACK丢失需要重传的情况,来达到快速回收TIME_WAIT状态连接的目的。
但上述理论在多个客户端使用NAT访问服务器时会产生新的问题:同一个NAT背后的多个客户端时间戳是很难保持一致的(timestamp机制使用的是系统启动相对时间),对于服务器来说,两台客户端主机各自建立的TCP连接表现为同一个对端IP的两个连接,按照Per-Host记录的最近接收时间戳会更新为两台客户端主机中时间戳较大的那个,而时间戳相对较小的客户端发出的所有数据包对服务器来说都是这台主机已过期的重复数据,因此会直接丢弃。这就是之前我描述的问题产生的根本原因,在公司的NAT防火墙内会有问题,而在防火墙外面就没有问题;设置net.ipv4.tcp_tw_recycle=1的服务器访问有问题,而没有进行内核参数优化的另一台服务器没有问题。
问题错误可以通过netstat -s 中的下面的记录来发现:
root@node17:~# netstat -s |grep -e “passive connections rejected because of time stamp”
19874 passive connections rejected because of time stamp
找到问题,解决问题的方法就简单了,设置如下:
#vi /etc/sysctl.conf
net.ipv4.tcp_tw_recycle = 0
#sysctl -p
问题解决,经验教训如下:
1、这次问题,是因为系统内核参数调整引起的,但问题现象看起来是网络问题,所以一直把问题导向查网络,浪费了很多时间
2、我们经常为提供服务器性能,来去调整内核参数。调整得当可以大幅提高服务器的处理能力,但如果调整不当,就会引进莫名其妙的各种问题,比如这次开启tcp_tw_recycle导致丢包,实际也是为了减少TIME_WAIT连接数量而进行参数调优的结果。我们在做系统优化时,时刻要保持辩证和空杯的心态,不盲目吸收他人的果,而多去追求因,只有知其所以然,才能结合实际业务特点,得出最合理的优化配置。
3、还有就是netstat -s 的TcpExt: 一定要仔细看,这为解决这次问题提供重要的线索。
如果我讲得不准确,下面搜索到的相关参考链接,大家可以也一起看一下(文中部分内容来自http://www.sdnlab.com/17530.html):
https://my.oschina.net/beiyou/blog/156182
https://saview.wordpress.com/2011/09/27/tcp_tw_recycle%E5%92%8Cnat%E9%80%A0%E6%88%90syn_ack%E9%97%AE%E9%A2%98/
http://www.sdnlab.com/17530.html
http://www.udpwork.com/item/11058.html

